科学计算用什么显卡,买什么显卡做科学计算
在2026年的科学计算场景中,选择显卡的核心逻辑已从单纯追求峰值算力转向“显存带宽+软件生态兼容性+能效比”的综合平衡,对于大多数中小企业而言,中高端专业卡或高性能消费级显卡的混合部署往往比盲目追求顶级旗舰更具性价比。
科学计算早已不再是超级实验室的专属,随着人工智能、生物制药、气象模拟等领域的爆发,算力需求呈现出碎片化与规模化并存的特征,很多初学者容易陷入一个误区,认为显卡越贵越好,或者只盯着理论浮点运算次数(FLOPS)看,在真实的工程落地中,数据在显存与内存之间的搬运速度,往往比计算本身更决定瓶颈所在,业内专家指出,显存带宽不足导致的“等待数据”时间,在复杂流体动力学模拟中可能占据总运行时间的40%以上,这比核心计算耗时还要长。
科学计算显卡选型的核心维度解析
选型过程不能拍脑袋决定,需要建立一套多维度的评估体系,我们将通过以下三个关键指标来拆解这一过程。
显存容量与带宽:数据的“高速公路”
显存是科学计算显卡的灵魂,在处理大规模矩阵运算或深度学习模型训练时,数据必须全部加载到显存中,如果显存溢出,系统被迫使用慢速的系统内存,性能会断崖式下跌。
- 容量门槛:对于常规深度学习训练,24GB显存是入门门槛;若涉及大语言模型微调或高分辨率3D渲染,建议起步48GB甚至80GB。
- 带宽关键性:带宽决定了数据吞吐能力,专业卡(如NVIDIA A系列或H系列)通常配备HBM2e或HBM3显存,带宽可达2TB/s,远超消费级显卡的GDDR6X,这种差异在科学计算中尤为明显,因为科学计算往往涉及大规模稀疏矩阵,对带宽极其敏感。
具体场景建议
- 小规模仿真:16GB-24GB显存足以应付大多数有限元分析。
- 大规模AI训练:必须选择配备HBM显存的专业级GPU,以确保多卡互联时的数据同步效率。
软件生态与兼容性:隐形的“成本中心”
硬件只是基础,软件生态才是决定开发效率的关键,NVIDIA的CUDA生态依然占据绝对主导地位,但AMD的ROCm和国产算力芯片的崛起正在改变格局。
CUDA兼容性:绝大多数科学计算库(如PyTorch, TensorFlow, CUDA-based CFD软件)都优先优化CUDA,选择NVIDIA显卡意味着最少的环境配置麻烦和最高的代码复用率。
- 跨平台挑战:若考虑AMD或国产芯片,需确认所用软件是否已提供原生支持或兼容层,据工信部数据,近年来国产算力芯片在特定垂直领域的适配率显著提升,但在通用科学计算库上的兼容性仍有提升空间。
能效比与散热:长期运行的“隐形账单”
科学计算任务往往需要连续运行数天甚至数周,功耗不仅影响电费,更直接影响数据中心的散热成本。
- TDP(热设计功耗):高端显卡TDP可达700W,这对电源和散热系统提出极高要求。
- 能效评估:计算“每瓦特算力”比单纯看“总算力”更具指导意义,在长时间运行的模拟任务中,高能效显卡能显著降低运营成本。
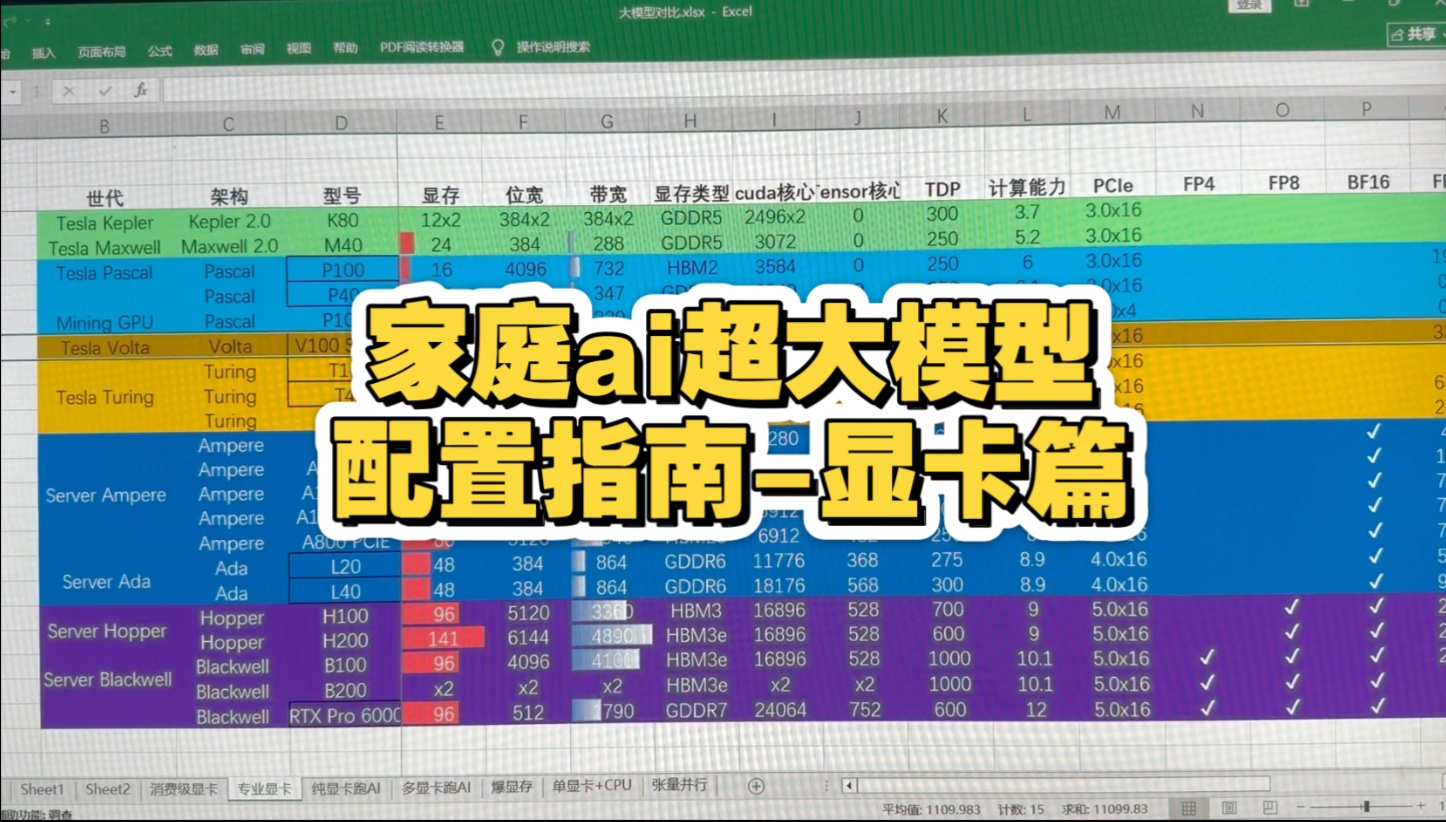
2026年主流科学计算显卡对比与场景推荐
为了更直观地展示不同显卡的适用场景,我们对比了当前市场主流的几类显卡。
| 显卡类型 | 代表型号 | 显存容量 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|---|
| 消费级旗舰 | RTX 4090 / 5090 | 24GB-32GB | 个人开发者、小规模AI训练、游戏渲染 | 性价比高,性能强劲,驱动成熟 | 显存容量有限,无ECC校验,多卡互联带宽受限 |
| 专业入门级 | RTX 6000 Ada | 48GB | 中型企业AI推理、中等规模仿真 | 大显存,支持ECC,稳定性高 | 价格昂贵,单卡绝对算力不如消费级旗舰 |
| 数据中心级 | H100 / H200 | 80GB+ | 大规模LLM训练、超大规模科学模拟 | 极致带宽,NVLink高速互联,高稳定性 | 价格极高,需专用服务器环境,功耗巨大 |
| 国产算力卡 | 华为昇腾910B等 | 64GB+ | 国内信创项目、特定AI训练 | 政策支持,供应链安全,性价比逐渐提升 | 生态适配需时间,开发者学习成本较高 |

如何根据预算选择科学计算显卡
预算是现实约束,不同预算区间有不同的最优解。
- 预算有限(<1万元):首选二手或全新消费级旗舰卡(如RTX 3090/4090),虽然显存较小,但通过模型量化或梯度检查点技术,仍可应对大多数入门级AI任务。
- 中等预算(1万-5万元):考虑单张RTX 6000 Ada或双卡RTX 4090方案,前者提供大显存和稳定性,后者提供高算力但需解决显存瓶颈。
- 高预算(>5万元):直接选择数据中心级GPU(如H100/H200)或组建多卡集群,软件优化和集群管理的重要性超过单卡性能。
科学计算显卡部署与优化实操指南
选对硬件只是第一步,正确的部署和优化才能释放全部潜力,以下提供几个关键的操作步骤。
环境配置与驱动安装
- 系统选择:推荐使用Ubuntu 22.04/24.04 LTS,其对CUDA和ROCm的支持最为完善。
- 驱动安装:使用官方.run文件或apt包管理器安装最新稳定版驱动,避免使用第三方PPA,以防版本冲突。
- CUDA Toolkit:确保CUDA版本与显卡驱动兼容,可使用
nvidia-smi命令查看当前驱动支持的CUDA版本。
性能监控与调优
- 实时监控:使用
nvtop或nvidia-smi实时监控GPU利用率、显存占用和温度,若发现利用率长期低于80%,可能存在I/O瓶颈或代码效率问题。 - 显存优化:在PyTorch中,启用
torch.cuda.amp进行混合精度训练,可显著减少显存占用并加速计算。 - 多卡并行:使用
torch.nn.DataParallel或torch.distributed进行多卡训练,注意,消费级显卡的多卡互联带宽较低,建议通过PCIe交换机或NVLink(若支持)优化通信。

常见故障排查
- OOM(显存溢出):减小Batch Size,启用梯度累积,或使用显存优化技术如Gradient Checkpointing。
- 驱动冲突:若更新驱动后无法启动,尝试进入恢复模式,卸载旧驱动并重新安装。
- 性能下降:检查显卡是否处于节能模式,确保BIOS中PCIe设置为Gen4/Gen5模式。
未来趋势:科学计算显卡的演进方向
随着AI大模型和科学计算的深度融合,显卡技术也在快速迭代。
- 专用AI加速:新一代显卡将集成更多张量核心,专门优化矩阵乘法运算,以应对大模型训练需求。
- 存算一体:未来可能出现存算一体芯片,打破冯·诺依曼架构瓶颈,大幅提升能效比。
- 国产替代加速:在政策支持和市场需求驱动下,国产科学计算显卡在生态适配和性能提升上将持续突破,为行业提供更多选择。
科学计算显卡选购Q&A
科学计算显卡和玩游戏显卡有什么区别?
科学计算显卡(专业卡)针对浮点运算精度、显存稳定性(ECC校验)和多卡互联带宽进行了优化,适合长时间高负载运行;游戏显卡则侧重图形渲染和峰值性能,性价比高但稳定性略逊,若预算充足且任务关键,首选专业卡;若预算有限且可接受一定风险,游戏卡也是可行方案。
2026年值得入手的科学计算显卡型号推荐?
若追求极致性能且预算充足,NVIDIA H100/H200是首选;若注重性价比,RTX 4090仍是主流选择;若关注国产替代,华为昇腾910B系列值得考虑,具体选择需结合软件生态和预算综合评估。
如何判断我的科学计算任务是否适合用显卡加速?
若任务涉及大规模并行计算(如矩阵运算、深度学习训练、流体模拟),且数据量足以填满显存,则显卡加速效果显著,若任务以串行逻辑为主或数据量极小,CPU可能更高效,建议先进行小规模测试,对比CPU与GPU的运行时间。


